
Être visible sur Google : Les critères confirmés
Cet article a plus de 4 ans.
Certaines informations peuvent donc être obsolètes. Gardez cela en tête lors de votre lecture.
Cet article fait partie d’un dossier sur les critères qui comptent vraiment pour être visible sur Google. Découvrez les autres articles en bas de page.
Il s’agit ici des critères sur lesquels Google a officiellement communiqué.
Soit pour confirmer qu’ils étaient bien pris en compte pour déterminer le classement d’un site dans les résultats de recherche, soit pour indiquer qu’ils ne l’étaient pas.
L’âge du domaine
Dans cette vidéo (en anglais – avec sous-titre), l’ancien employé de Google Matt Cutts affirmait que :
La différence entre un domaine vieux de six mois et un autre vieux d’un an n’est pas si importante.
Matt Cutts
En d’autre termes, Google utilise l’ancienneté du domaine. Mais ce n’est pas un critère très important.
Cela a encore été confirmé récemment par Google. Toutefois, plus un site est vieux, plus Google dispose de données sur ce dernier. Mais cela n’est pas lié au nom de domaine seul.
Historique du domaine
Lorsque vous achetez un nom de domaine, il est possible que celui-ci ait déjà été acheté puis revendu ou laissé à l’abandon.
Il est également possible que le domaine ait été pénalisé par Google dans le passé.
La plupart du temps, le transfert de propriété d’un nom de domaine suffit à remettre les compteurs à zéro.
L’extension de nom de domaine est liée à un pays
Google utilise un grand nombre de critères pour personnaliser ses résultats en fonction du pays, voire de la ville.
De ce fait, utiliser une extension liée à un pays (.fr, .ca, .aq, .bw…) permet à Google de relier votre nom de domaine à un pays.
À l’inverse, si vous utilisez une extension géographique pour former un jeu de mot, cela peut envoyer un signal contradictoire à Google.
Exemple : le site américain last.fm utilise l’extension .fm pour indiquer un lien avec la radio, la bande FM. Or, .fm est l’extension géographique de la Micronésie.
L’impact de ce critère — comme tous ceux liés au nom de domaine — est assez faible. L’influence est plus indirecte et va jouer sur comment les internautes vont percevoir votre site.
Présence du mot-clef dans la balise title
La balise title est une balise HTML qui contient du contenu affiché notamment dans l’onglet du navigateur, les réseaux sociaux et outils de messagerie instantanée et dans les résultats des moteurs de recherche.
Compte tenu de sa position dans les moteurs de recherche la balise title constitue la première expérience qu’ont les internautes avec votre site. Il est donc important de bien la soigner.

Exemple de balise title dans Google 
Exemple de balise title dans Slack 
Exemple de balise title dans le navigateur
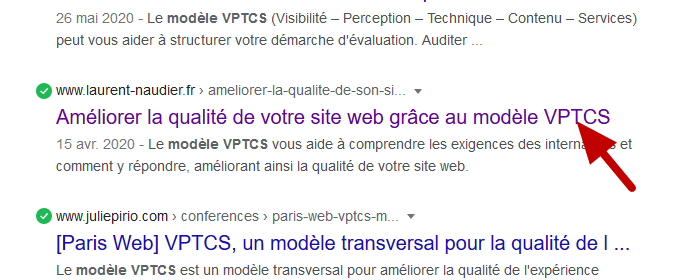

Google a confirmé en 2016 que ce critère était pris en compte pour déterminer le classement d’un site. Même s’il s’agit d’un critère important, il l’est moins qu’il y a quelques années.
Le moteur de recherche est également vigilant à ce que le contenu ne soit pas bourré de mot-clef car cela représente une mauvaise expérience utilisateur.
Présence du mot-clef dans la balise méta description
Il s’agit ici du court texte qui apparaît en dessous du titre dans les moteurs de recherche et sur les réseaux sociaux.
Dans un article de 2009 (contenu en anglais), Google a indiqué que cette balise n’était pas un critère de classement.
Cette balise a toutefois un impact important sur le taux de clic, qui lui est un critère de classement indirect.
Le mot clef apparaît dans les titres de niveau 1
On entend par titre de niveau 1 (ou titre h1) le titre de la page. Il est à différencier de la balise title car le contenu peut être différent et ce titre apparaît dans le navigateur de l’internaute.
Par exemple, pour ma page « Audit de site web », le contenu de ma balise title est différent de celui de mon titre de niveau 1 :
- Balise title : Audit de site web ~ Faites un bilan de santé de votre site.
- Titre de niveau 1 : Audit de site web

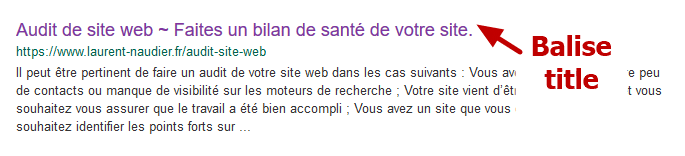
Certaines études ont montré que l’usage des titres de niveau 1, avec ou sans mot-clef, n’a qu’une portée limitée sur le classement de votre site dans Google.
Il serait même possible de s’en passer.
Ce qui semble en revanche avoir de l’importance pour Google c’est la hiérarchie des contenus, qu’elle soit visuelle ou technique.
Cela a été confirmé en 2019 par Google :
Your site can do perfectly fine with no H1 tags or with five H1 tags.
Source : John Mueller (Google) – vidéo en anglais, sous titrée en anglais
Ainsi, pour Google, que nous n’ayez aucun titre de niveau 1 ou que vous en ayez 5 par page ne change rien.
En effet, si vous n’utilisez pas de titre, Google va essayer de comprendre par lui-même comment votre contenu est hiérarchisé.
Si pour Google l’usage ou non des titres de niveau 1 ne change rien, il est tout de même fortement recommandé de les utiliser.
La principale raison, qui devrait être la seule, est que les titres aident à l’accessibilité de votre site. Ils sont en effet lus par les lecteurs d’écran utilisés par les internautes aveugles ou mal-voyants.
Enfin, Google n’est pas le seul moteur de recherche au monde, et d’autres moteurs, comme Bing, les utilisent comme critère de classement.
Nombres d’occurrences et fréquence d’apparition d’un mot-clef dans la page
Pendant longtemps, les moteurs de recherche utilisaient la notion de densité de mot-clef pour déterminer sur quelle requête cherchait à se positionner un site web.
Déjà en 2012 l’importance de cette méthode était remise en cause par Google.
Avec le développement de l’intelligence artificielle, Google est capable de comprendre tout seul le sujet d’un site web. Ce qui réduit encore l’importance de ce critère.
Il n’est donc plus nécessaire de bourrer son contenu d’occurrences d’un mot-clef pour espérer se positionner dessus.
Au contraire, il est important de faire preuve de richesse linguistique et d’alterner entre le mot-clef cible, un synonyme, un autre mot du même champ lexical, un antonyme…
Cela renforcera la qualité de votre contenu.
Le sujet est traité en profondeur
Il est prouvé qu’il existe une corrélation entre la façon dont est couvert un sujet et le classement de la page dans Google.
Un article traité en profondeur, en couvrant différents angles sera mieux positionné qu’un contenu qui ne traite que d’un angle en particulier.
Toutefois, une corrélation n’est pas une preuve qu’il s’agit d’un critère utilisé par Google.
En revanche, il est certain que Google accorde beaucoup d’importance à la qualité du contenu et au concept d’E-A-T (Expertise, Authoritativeness (Autorité), Trustworthiness (Confiance)).
Contenu de l’ancre du lien
Le terme d’ancre désigne le texte du lien sur lequel vous allez cliquer.
Ce contenu est essentiel pour Google car il transmet du sens sur la thématique de la page de destination et agit comme un mot-clef déporté.
Par exemple, si un site tiers fait un lien vers ma page Audit de site web, l’ancre « améliorez votre site web grâce à un audit » aura plus de poids que « en savoir plus ».
Découvrez comment donner du sens à vos ancres :
À noter que ces conseils sont également valables pour les liens internes.
En outre, l’emplacement du lien a son importance : un lien présent de manière contextualisée dans le contenu aura plus de poids qu’un lien dans le pied de page par exemple. A fortiori s’il est placé haut dans le contenu.
Autorité de la page d’origine du lien
Dès l’origine de son moteur de recherche, l’autorité de la page d’origine d’un lien constitue un facteur important. C’est toujours le cas en 2020.
Les votes émis par des pages considérées comme « importantes » ont une valeur plus grande et contribuent au classement d’autres pages dans la catégorie des pages « importantes ».
Les liens disposent des bons attributs
Depuis 2005, pour indiquer aux moteurs de recherche s’ils devaient suivre ou non un lien, on pouvait utiliser l’attribut rel=nofollow. Comme son nom l’indique, cet attribut sert à demander aux moteurs de ne pas suivre un lien.
En septembre 2019, Google a proposé une évolution des attributs de liens, afin d’affiner sa compréhension des relations qui lient deux sites entre eux.
Ainsi, le moteur de recherche (rejoint début juillet 2020 par Bing) reconnaît deux nouveaux attributs en plus de l’attribut historique rel=nofollow :
rel="sponsored": pour les liens publicitaires, faisant l’objet d’un sponsoring ou d’un échange, monétaire ou non.rel="ugc"(User Generated Content) : pour les liens créés par les utilisateurs et utilisatrices d’un site web, comme des discussions d’un forum ou les commentaires d’un blog.
Par exemple, depuis WordPress 5.3, tous les liens présents dans les commentaires d’un article ont l’attribut rel=ugc car ce contenu est généré par les internautes.
À noter qu’il est possible d’utiliser deux attributs (ex : rel="ugc nofollow" ou rel="sponsored ugc").
En outre cet attribut est désormais considéré comme un indice et non comme une consigne. Les moteurs de recherche peuvent donc les ignorer.
Liens présents sur tout le site
Les liens dit « sitewide » sont des liens présents sur toutes les pages du site, que ce soit dans le pied de page ou dans la colonne latérale.
Selon la taille du site, cela peut sembler intéressant d’avoir ce type de lien.
Toutefois, Google ne va garder que quelques liens parmi tous ceux créés.
Pour en savoir plus sur cette problématique, je vous invite à consulter cette vidéo du site Abondance (oui encore une ^^) :
Dynamisme de la communauté
Google a confirmé à plusieurs reprises qu’un site avec une communauté riche et active était une bonne chose à ses yeux.
Ainsi, le nombre de commentaires, les réponses des internautes les uns aux autres, vos réponses aux commentaires… sont autant de signaux positifs envoyés à Google.
Les commentaires d’un article de blog ou d’un produit vendu sur un site marchand sont également des moyens de fournir à Google du contenu supplémentaire à analyser et peuvent l’aider à comprendre la thématique de la page.
À noter toutefois que ce n’est pas un critère très important. Ce qui compte, c’est avant tout la qualité de votre contenu.
Utilisation de métadonnées
Une métadonnée est une donnée qui sert à définir ou décrire une autre donnée.
Par exemple : ce dossier constitue la donnée de référence. Les métadonnées associées pourraient être : la date de publication, l’auteur, le nombre de commentaires…
Google est friand de métadonnées car elles l’aident à enrichir sa page de résultats.
Pour cela, il est recommandé d’utiliser le balisage Schema.org, un langage de structuration de données mis au point par Google, Yahoo! et Bing.
Bien que ce soit pas un critère de classement en tant que tel, l’utilisation de ce format vous permettra de bénéficier des résultats enrichis :
Vitesse de chargement du site
Google utilise le temps de chargement d’un site comme critère de classement depuis 2010. Bing l’utilise depuis 2012.
En 2018, ce critère a été étendu aux recherches mobiles.
Google a confirmé en avril 2020 que le poids accordé à celui-ci était très faible. Il n’intervient généralement que pour départager deux sites qui seraient « à égalité » sur une recherche donnée.
En revanche, ce facteur est utilisé pour pénaliser certains sites très très lents (et donc indirectement en booster d’autres).
Toutefois, l’immense majorité des sites ne sont pas concernés par ce critère car ils ne sont ni très très rapide, ni trop lent.
Comme le dit John Mueller :
[…] si vous êtes en train de régler des millisecondes, ce n’est probablement pas la meilleure utilisation de votre temps si vous ne vous souciez que du référencement. (…) Certains sites très très rapides peuvent cependant recevoir un « boost » en termes de classement, car si on « pénalise » certains, d’autres en profitent.
Source : Abondance
En revanche le temps de chargement du site est très important pour l’internaute.
Voici quelques outils qui vont vous aider à améliorer le temps de chargement d’un site ou d’une page spécifique :
Vitesse de chargement avec Google Chrome
Depuis 2018, Google utilise les données issues de visites de « vrais » internautes pour déterminer le temps de chargement d’une page.
C’est ce que Google appelle le « Chrome User Experience Report » est qui est intégré dans l’outil Google Page Speed Insight mentionné précédemment.
Si ces données permettent au moteur de recherche d’avoir une meilleure compréhension de la vitesse de chargement de la page, ce n’est pas un critère de classement.
Les informations du Whois sont-elles publiques ou privées ?
Le Whois, est un service qui permet de connaître un certain nombre d’informations relatives à un nom de domaine. Des informations comme : le nom du/de la propriétaire, auprès de quel service il a été acheté, à quelle date, pour combien de temps…
Le/la propriétaire du nom de domaine a alors la possibilité de rendre ces données publiques ou privées.
Cette technique étant utilisée à la fois par des personnes qui veulent protéger leur vie privée et par des spammeurs, Google peut la percevoir comme un signal négatif, montrant qu’il y a quelque chose à cacher. Surtout si vous possédez un grand nombre de sites, tous avec les informations du Whois masquées.
De manière isolée, l’impact de ce critère est quasi nul. Si votre site est de bonne qualité, et que le nombre de signaux positifs excède le nombre de signaux négatifs, vous n’avez rien à craindre.
Utilisation du format AMP
AMP (pour Accelerated Mobile Page) est une technologie lancée en 2016 par Google. Elle se matérialise par la création de deux nouveaux formats : AMP HTML et AMP JavaScript.
Elle a pour objectif d’accélérer l’affichage d’une page web lorsqu’elle est consultée sur un smartphone ou une tablette.
Pour cela, la page est réduite à son strict minimum (le contenu) et convertie en un format statique.
En mars 2020, Google a confirmé que l’usage ou non d’AMP n’était pas un critère de classement (source : Abondance).
L’optimisation pour l’algorithme Hummingbird
Il s’agit du nom donné à un algorithme de pertinence lancé en 2013 par Google.
Son objectif est d’améliorer la pertinence des résultats fournis par le moteur de recherche notamment lorsque la recherche est demandée en langage naturel (sous forme de question par exemple).
C’est avec cet algorithme que Google a commencé à favoriser la qualité à la quantité et à introduire la recherche sémantique.
Il a aussi posé les bases de la recherche vocale et amélioré grandement la recherche locale.
Si votre site est postérieur à 2013, il est fort probable que vous respectiez déjà les recommandations liées à cet algorithme.
Présence de contenu dupliqué
Est considéré comme contenu dupliqué tout contenu identique (ou modifié légèrement) qui est accessible depuis sur Internet depuis deux URLs différentes (issues du même site ou non).
Exemple :
- Vous vendez les mêmes produits, avec la même description sur différentes places de marché ;
- Un site reprend une partie d’un de vos articles pour en faire la promotion (ou pour plagier le contenu) et l’article n’est pas suffisamment long pour que Google comprenne qu’il s’agisse d’un extrait ;
- Vous publiez vos articles en intégralité dans vos flux RSS ;
- Vous publiez les mêmes contenus sur les versions française et belge francophone de votre site ;
- Il n’y a pas de redirection entre les versions avec et sans « www » de votre site et/ou avec et sans « https »
- …
Il peut donc être volontaire ou subit.
Officiellement, Google n’applique pas de pénalité en cas de contenu dupliqué. Toutefois, le moteur de recherche applique un filtre qui exclus les doublons, ce qui peut laisser penser que certains contenus sont pénalisés.
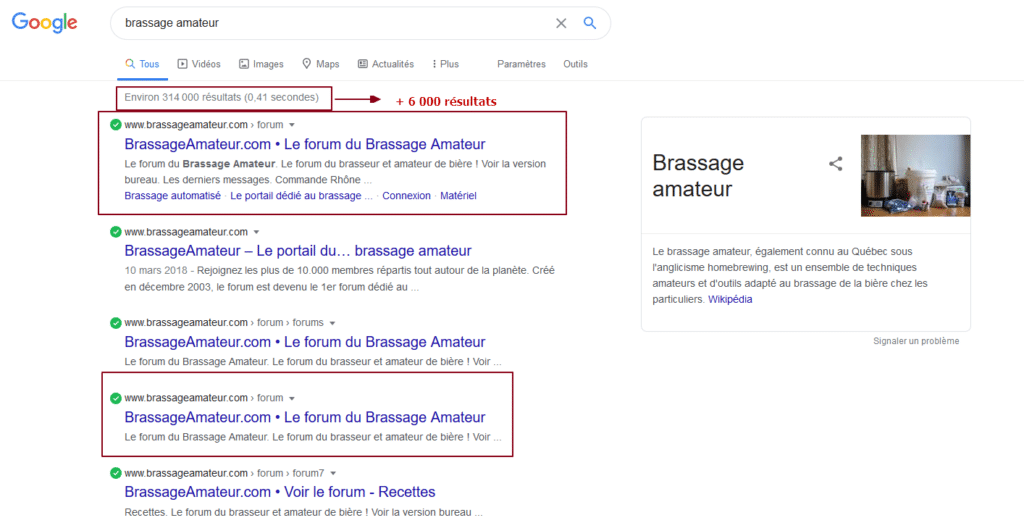
Pour voir la différence, il vous suffit de rajouter le paramètre &filter=0 à l’URL.
L’exemple ci-dessous montre les premiers résultats pour la requête « brassage amateur » en désactivant le filtrage des doublons. On constate que le nombre de résultats augmente de 6 000 et que certains sites sont présents deux fois.
Usage de l’attribut rel=canonical
En 2009, Yahoo!, Google et Bing se sont mis d’accord sur la création de l’attribut HTML rel=canonical – qui s’applique sur la balise HTML link — qui vise à lutter contre le contenu dupliqué.
L’objectif est d’indiquer aux moteurs de recherche quelle est la page d’origine. Ainsi, en cas de contenu dupliqué, ils ont un indice sur l’origine du contenu initial.
Cette information est généralement placée sur les pages de contenu dupliqué interne au site et renvoie vers la page originale.
Pour mieux comprendre le fonctionnement de cette attribut, je vous conseille cette vidéo du site Abondance :
À noter qu’il ne s’agit pas d’un critère en tant que tel, mais cette technique peut vous éviter d’être impacté par le filtre mentionné précédemment.
Optimisation des images pour le SEO
S’il ne s’agit pas à proprement parler d’un critère de classement du site, les images sont un excellent moyen de générer du trafic et leur optimisation ne doit pas être négligée.
Parmi les principales optimisations à appliquer, on peut citer :
- Travaillez le nom du fichier (préférez spectacle-jeremy-ferrari-lille.jpg à IMG4014-2016.jpg)
- Si l’image est porteuse de sens, indiquez un texte alternatif
- Renseignez une description ou une légende
Ces quelques éléments donnent des indications aux moteurs de recherche sur le contenu de l’image.
Fraîcheur du contenu
Officiellement, Google ne favorise pas le contenu « frais », c’est-à-dire qu’il ne classe pas les pages en fonction de leur date de publication.
C’est probablement vrai pour la plupart des requêtes, mais il y a des exceptions :
- Les contenus liés à l’actualité (ex : convention climat),
- Les requêtes contenant une date (ex : concert yodelice 2020),
- Les événements récurrents (ex : la finale de la Ligue des Champions de football),
- Lorsque le filtrage temporel des résultats est activé.
En outre, le moteur de recherche affiche la date à côté de certaines requêtes.
S’il est avéré que Google prend en compte la date de publication ou de mise à jour d’un contenu, son réel impact sur le classement d’un site semble surtout dépendre du type de requête.
Structure de l’URL
L’URL est bien souvent la première chose que voient les moteurs de recherche de votre site.
Même si ce n’est pas un critère de classement très important, ce n’est pas quelque chose à négliger.
Bien qu’il n’y ait pas de formule magique, il existe quelques règles à respecter pour optimiser la structure à la fois pour les internautes et les moteurs de recherche. Ainsi, vos URLs devront être :
- Humainement lisible : d’après-vous, entre https://www.laurent-naudier.fr/audit-site-web et https://www.laurent-naudier.fr/?p=27441 quelle URL est la plus optimisée ?
- Représentative de votre arborescence : si votre page est située dans une rubrique puis une sous-rubrique, votre URL doit représenter cette structure.
- Sans mots superflus : les mots comme le, la, du… n’apporte aucun sens et génèrent du bruit. Il est donc recommandé de les supprimer de l’URL. Séparez également les mots avec un tiret «
-» et non un underscore «_». - Favorisez le protocole https au protocole http : Google favorise les URL sécurisées, mais le gain est très faible (voir ci-après).
Utilisation du HTTPS
Depuis quelques années, Google pousse à l’utilisation du protocole sécurisé HTTPS à la place du protocole HTTP, moins sécurisé.
Le poids de ce facteur est toutefois assez faible et sert essentiellement à départager deux sites qui seraient à égalité sur l’ensemble des autres critères.
Longueur de l’URL
Des études menées par des acteurs de l’industrie du SEO ont montré que les URLs longues étaient moins bien classées que les URLs courtes.
L’impact de ce critère a toutefois été démenti (en anglais) par John Mueller en février dernier.
Présence de liens d’affiliation
Si votre site contient un grand nombre de liens d’affiliation, cela envoie un signal négatif à Google.
De l’aveu même de Google, il est peu probable que de tels sites soient bien classés dans les pages de résultats.
Il est également recommandé d’utiliser l’attribut rel = sponsored (voir plus bas) pour de tels liens.
Optimisation de la page et du site pour les supports mobiles
En octobre 2017 Google a déployé l’Index Mobile First (IMF) qui marque un changement dans la façon dont Google explore un site web : avant l’IMF, le site était exploré uniquement dans sa version « bureau », avec l’IMF, Google explore le site uniquement dans sa version « mobile ».
Depuis 2017 et jusque septembre 2020 mars 2021, Google bascule petit à petit sur ce nouvel index l’ensemble des sites qui figure déjà dans ses résultats de recherche.
À partir de septembre 2020 mars 2021, c’est l’index mobile qui sera utilisé par défaut.
En savoir plus sur l’Index Mobile First :
Présence d’un fil d’Ariane
Comme dans la légende grecque, sur un site web le fil d’Ariane vous aide à retrouver votre chemin dans l’arborescence.

Il est donc très utile aux internautes et est particulièrement apprécié des moteurs de recherche car il permet de catégoriser l’information de la page dans les résultats de recherche.
Site piraté
Si votre site a été piraté, il est possible qu’il soit désindexé de Google le temps que vous corrigiez le problème.
À noter qu’il peut arriver que votre site soit désindexé par erreur. C’est ce qui est arrivé en 2018 au site spécialisé dans les moteurs de recherche Search Engine Land (contenu en anglais) qui s’est vu disparaître de Google pendant une journée, à la suite d’une erreur.
Le poids de la page dans le fichier sitemap.xml
Ce fichier, optionnel si votre arborescence est claire, liste l’ensemble des URLs ainsi qu’un certain nombre d’informations (date de dernière modification, fréquence de mise à jour…). Il facilite ainsi le parcours du site par les moteurs de recherche.
Il est possible de donner à chaque page un poids, afin d’aider les moteurs à comprendre quelle sont les pages les plus importantes du site, surtout si vous avez plusieurs pages sur le même thème.
De l’avis du Googler (salarié de Google) Gary Illyes, cette information n’est pas prise en compte par Google.
Emplacement du serveur
L’emplacement géographique du serveur qui héberge votre site a longtemps été utilisé par Google pour influencer les résultats des recherches locales.
En 2017, Google, via John Mueller, a indiqué que ce critère n’était plus pris en compte. Le moteur se base avant tout sur l’extension utilisée ou sur l’indication de ciblage renseignée dans l’outil Google Search Console.
Présence de contenu supplémentaire utile
En mai 2019, Google publiait une nouvelle version de son guide destiné aux « Quality Raters ».
Parmi les différents critères, on retrouve le recours à des contenus utilitaires (ex : un calculateur, un convertisseur, un simulateur…).
Pour Google, la présence d’un tel outil est un gage de qualité, mais ce n’est pas un critère de classement en tant que tel.
Présence d’interstitiels et de pop-ups
Cela concerne essentiellement la version mobile de votre site.
Si celle-ci présente des interstitiels ou des pop-ups publicitaires, votre site sera pénalisé par Google. A fortiori si la pop-up couvre tout l’écran.
Ne sont pas concernés les pop-ups et interstitiels liés à des obligations légales (gestion des cookies, sites interdits aux mineurs…)
Voici quelques exemples de pratique pénalisées :

À lire ensuite :